

SpeechRecognition is a module that to helps Python scripts interact with outside Speech-to-Text engines. It’s important to note here that the module doesn’t actually transcribe audio on its own—it’s more like a sports agent, connecting you with talent.
And some of that talent can be had or tried free of charge. Today, I’ll be looking exclusively at those.
For the test audio, I turned to a recent Vlog Brothers video about the many John Greens. Here’s the results of the first 15 seconds of John’s monologue in four different Speech-to-Text options: Google, Pocket Sphinx, IBM, and Houndify.

None were perfect, but they came darn close.
Based solely on that, I’m leaning toward IBM and Houndify for accuracy. Pocket Sphinx is my third place choice because, although it’s the least accurate, it can be used offline. What Google did translate was fairly accurate, but it skipped pieces where John was talking fast. And I want something that can handle fast-talkers.
Let’s talk about the script. First, you’ll need to go through and install SpeechRecognition. If you’ve never installed a 3rd party module, take a look at this post breaking it down. Once that’s done, you can prepare your audio with this block of code, substituting your own .wav file for WAVTest below.
import speech_recognition as sr
AUDIO_FILE = ("C:\\Users\\Desktop\\WAVTest.wav")
r = sr.Recognizer()
with sr.AudioFile(AUDIO_FILE) as source:
audio = r.record(source)
A complete Python script is available over at GitHub courtesy of Uberi, but for testing purposes, I just added the specific engine to the end of the above block to get the transcription.
I’m starting with my least favorite. Google Speech Recognition… was a confusing beast. Bad gateway errors galore.
The culprit on those is, according to this post, due to content limitations. Their API page lists the content limit at about 1 minute, but I get the error with any clips longer than about 15 seconds.
In spite of testing pretty regularly throughout the day never actually hit their daily limit though. So if you have multiple short clips, this isn’t a bad option.
And, as mentioned, its accuracy is decent. Minus thinking “Hank” was “Nick.”
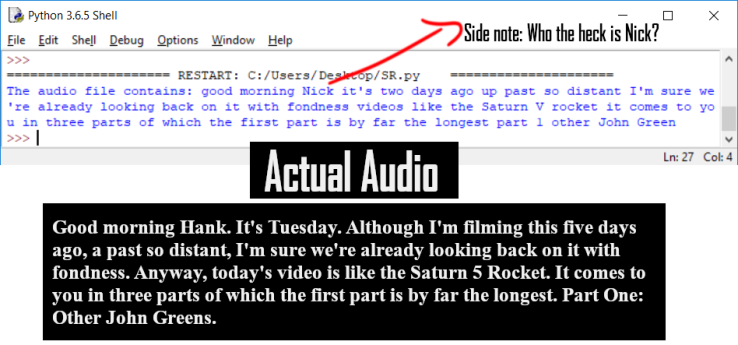
Code:
try:
print("The audio file contains: " + r.recognize_google(audio))
except sr.UnknownValueError:
print("Google Speech Recognition could not understand audio")
except sr.RequestError as e:
print("Could not request results from Google Speech Recognition service; {0}".format(e))
Pocket Sphinx
Ok, huge benefit here. You can be offline. Keep in mind, you have to install the pocketsphinx module before running it, but otherwise, this is a pretty hands-off pick.
It transcribed a full 4 minutes of John Green ranting without complaint, so you don’t have to be as concerned about cutting your clips into digestible pieces.
Everything’s a trade-off though. It gave me “operate” instead of “arguing”, “forces” instead of “horses”, and “common book” instead of “comic book”. Be prepared for some revision after, but personally, I still feel like its worth it, especially if you’re averse to setting up accounts on additional sites, like you’ll need to do with both Houndify and IBM.

Code:
try:
print("The audio file contains: " + r.recognize_sphinx(audio))
except sr.UnknownValueError:
print("Sphinx could not understand audio")
except sr.RequestError as e:
print("Sphinx error; {0}".format(e))
IBM
Ok, to make IBM work, you gotta sign up for an account. Don’t panic though. They have a “Lite” plan that doesn’t require a credit card, and it gives you 100 free minutes per month. Depending on your usage, the Standard plans aren’t half-bad in terms of pricing.
And it, like Pocket Sphinx, was able to transcribe the full 4 minutes of John’s audio without error. No need to break up your clips. Huzzah.
Their website isn’t the most user-friendly in the world though, so brace yourself. Once you’re in, go to your dashboard. Under your Cloud Foundry Services, click the one that says “Speech to Text-ct”. That’ll take you to a box where you can access your cool new credentials—a username and password.
That’s what you’ll plug into the Python before running it.
To be totally honest, this one has become my favorite because of both its accuracy and its ability to handle longer clips. However, I feel like Houndify is still worth mentioning because it’ll give you more free minutes per month.

Code:
IBM_USERNAME = "Long Alphanumeric String"
IBM_PASSWORD = "Long Alphanumeric String"
try:
print("The audio file contains: " + r.recognize_ibm(audio, username=IBM_USERNAME, password=IBM_PASSWORD))
except sr.UnknownValueError:
print("IBM Speech to Text could not understand audio")
except sr.RequestError as e:
print("Could not request results from IBM Speech to Text service; {0}".format(e))
Houndify
The Houndify website indicates every second of audio is .25 credits. A free account comes with 100 credits per day. In theory, that translates to 400 seconds of speech-to-text per day, or about 6.6 minutes. Times 30 days in a month, that’ll get you 198 minutes (double what IBM will do).
Keep in mind, those 6.6 minutes will need to be broken into different requests. I got a full minute to process once, but frequently encountered the “Remote end closed connection without response” error with anything around that size.
I consistently ran 45-second clips without error, so if your clips are that length or smaller, a Houndify account is worth it.
To get set up after getting an account, go to your dashboard and create a client. Give it a name, pick a platform, and then enable the Speech-to-Text domain.
That’ll get you a Client ID and Key. Plug that in, and presto. Accuracy-wise, I think this one technically did the best on my John Green test. No mention of Hank, but John really blazed through that intro.

Code:
HOUNDIFY_CLIENT_ID = "Long String from Houdify"
HOUNDIFY_CLIENT_KEY = "Long String from Houdify"
try:
print("The audio file contains: " + r.recognize_houndify(audio, client_id=HOUNDIFY_CLIENT_ID, client_key=HOUNDIFY_CLIENT_KEY))
except sr.UnknownValueError:
print("Houndify could not understand audio")
except sr.RequestError as e:
print("Could not request results from Houndify service; {0}".format(e))
Suggestions for other engines I can incorporate into my Python scripts? Pop ’em in the comments below.

Nice post.
LikeLiked by 1 person
In case I haven’t said before, really like your posts: the content, structure, and to-the-point graphics. Thanks!
LikeLiked by 1 person
Appreciate the kind comment dennisaa! Recovering from a move, but will be returning to GifGuide tutorials soon 🙂
LikeLiked by 1 person