

I live in Miami.
And I can tell you from experience, the Craigslist housing listing page is the 8th circle of hell. Evil pits, horned demons, real estate agents posting fake listings as bait for new clients.
Who has the time to sift through all that?
Personally, I think it’s a structural problem. You have to click into each page to get a full description of the apartment. That’s where you get a lot of clues about whether something is fishy or not. Too many spelling errors, everything in caps, too good to be true claims, or phone numbers of agents you’ve already called and ruled out.
So today we’re going to scrape the housing search results into an Excel document for easier reference.
Let’s talk about the Craigslist.org URL for a second. The base is made up of the city name.craigslist.org/search/roo?, and after that, you can throw in search parameters with & signs. I hate Craigslist listings without pictures (who doesn’t post pictures?), so I want to filter those out. I’m bundling duplicates to avoid inflation.

For testing purposes, I’ve opted for a few more parameters as well. This is the full URL that I’ll be using in the code:
https://miami.craigslist.org/search/mdc/sub?max_price=900&bundleDuplicates=1&hasPic=1&min_price=400
Step 1: Cut out the Listing URLs
Ok, now let’s strip out the pieces we want. If you go to Craigslist, right click the listing URL, and then hit Inspect Element, you’ll see each listing’s URL and description couched inside a class called “result-title hdrlnk.” Isolating that is our first step.

It isn’t as complicated as you might think. First, you retrieve the page’s HTML with the requests module. Then you plug that into BeautifulSoup, and just call it soup.
Then you shove the soup into a for loop. You can use the find_all method to filter for a specific class, like “result-title hdrlnk.” And while you’re in there, you can grab the link.
import requests
import bs4
url='The URL'
res = requests.get(url)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, 'html.parser')
for a in soup.find_all("a", class_="result-title hdrlnk"):
print(a.string)
print(a.get('href'))
The result on that is going to be a large data dump, but only the data we need.
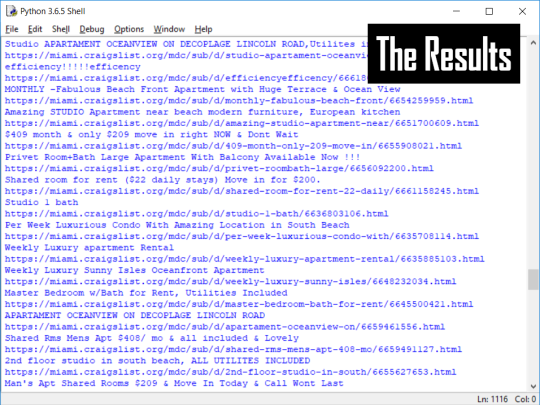
Step 3: Stash the URLs into a Dictionary
My new favorite thing in the world is this function posted by CoryKramer on Stackoverflow.com. It adds key/value pairs to a dictionary if they don’t already exist.
listings = dict()
def addlisting(desc, url):
if desc in listings:
print('Already listed')
print(desc)
else:
listings[desc] = url
Once you have that in place, you can call it in another function that uses the listing header as the key and the URL as the item.
def getSearchPageListings(url):
res = requests.get(url)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, 'html.parser')
for a in soup.find_all("a", class_="result-title hdrlnk"):
addListing(a.string, a.get('href'))
Step 4: Loop Through Each Listing for Descriptions
Ok, I was up till 2am last night trying to figure out how to get the body text out of each listing’s page, and I was genuinely stumped. Beautiful Soup wouldn’t let me use find_all with section classes or section ids. If you happen to know why that’s not allowed, please post in the comments.
As a band-aid, I used .get_text() to just yank out everything that gets displayed on the page. That returns a giant string though, oddly inflated by empty lines.
To resolve that, I stole a function from Ian Rolfe’s Journal, Random Jibberings on Programming (which I think he grabbed from Google, but I’m not tracing it back further than that).
def strip(txt):
ret=""
for l in txt.split("\n"):
if l.strip()!='':
ret += l + "\n"
return ret
When you run the entire text of the listing page through that function, this is what you’ll see:

Notice how everything you want to know comes after “(google map)” and before “email to friend.” You can slice out that part of the string using [Index@Start:Index@End]. And if you don’t know the exact number where you want to start, you can use .find to get your start and end points.
desc = strip(soup.get_text())
desc = desc[desc.find("google map")+12:desc.find("email to friend")]
Adding 12 to “google map” will get rid of the 12 characters in “google map.”
Keep in mind, this structure only works on listings that come with coordinates. On listings that don’t, you won’t see “google map” in the text. I don’t like postings without locational data though, so I’m excluding those.
When you use .find to try to locate something that isn’t there, it’ll return a negative 1. You can just make Python print “No map” on those, like this:
bodysum = dict()
bodyText = dict()
def MineListing(listUrl):
res = requests.get(listUrl)
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, 'html.parser')
desc = strip(soup.get_text())
if (desc.find("google map") == -1):
print('No map.')
else:
bodysum[listUrl] = desc[desc.find("google map")+12:desc.find("QR Code Link to This Post")]
bodyText[listUrl] = desc[desc.find("QR")+25:desc.find("email to friend")]
Step 5: Push the Data into Excel
Here’s the fun thing about Python. You don’t actually need an Office subscription to edit workbooks when you’re using openpyxl. You can write values into cells like so:
import openpyxl
wb = openpyxl.Workbook()
ws = wb.create_sheet("Listings", 0)
i=1
for key in bodyText:
ws.cell(row=i, column=1).value = listings[key]
ws.cell(row=i, column=2).value = bodysum[key]
ws.cell(row=i, column=3).value = bodyText[key]
i += 1
wb.save("C:/Users/Desktop/Craigslist.xlsx")
Put it all together, and you’ll have this bright, shiny new workbook, ready to go.

Take a look at the full script over at Gist.
In the near future I’m hoping to write a macro to filter out listings I don’t want to look at. I’m closing out today’s post with a short list of elements I’m hoping to script out. Have ideas for more? Post ’em below.
Sketchy Things to Filter Out:
- Any listings that aim to take you off-site
(!!! FOR AN APPOINTMENT !!! Contact only here => http://www.RoomSublet.us) - Too Good to Be True Pricing
- Grammar that looks like it was generated by a bad translation service
- Suspiciously professional photos that may have been lifted off of stock sites
- Multiple post updates, spanning more than a month

